你的位置:世博体育官网2024安卓最新版_手机app官方版免费安装下载 > 资讯 >
世博体育越来越难以满足指数级增长的智能分娩需求-世博体育官网2024安卓最新版_手机app官方版免费安装下载
发布日期:2025-07-31 05:58 点击次数:205

来源——硬件天下
咱们正站在AI狂飙的黄金期间——短短半年,环球顶尖模子“智力”飙升50%;2025年果然每周都有重磅模子登场;从诳言语模子到多模态架构,七类模子架构全速迭代。
当传统“暴力堆卡”的西席方法,越来越难以满足指数级增长的智能分娩需求。AI产业亟需要一场“后果创新”,即构建新一代大型东说念主工智能盘算基础设施,以应答生成式AI进化。
国内GPU厂商摩尔线程在WAIC 2025前夜出招了,要用国产全功能GPU打造一个AI“超等工场”,直击大模子西席后果的瓶颈。

这座AI工场的“产能”,有一齐硬核公式来臆测:
AI工场分娩后果 = 加快盘算通用性 × 单芯片灵验算力 × 单节点后果 × 集群后果 × 集群康健性
摩尔线程的杀手锏“全功能GPU”,便是这座“AI工场”的腹黑。
把柄功能结构别离,GPU可分为图形GPU、GPGPU(通用盘算GPU)与全功能GPU。既然是全功能GPU,你不错表示为,既能作念图形,也能作念AI,还不错作念通用盘算、科学盘算等。环球范围内,也仅有NVIDIA掌持的顶端期间。而摩尔线程是国内惟一从功能上不错对标英伟达的国产全功能GPU企业。
自2020年竖立以来,摩尔线程一直勤恳于于全功能GPU的研发与创新。全功能GPU具备更强的通用性,不仅不错作事数据中心,也具备下千里至虚耗端的后劲,是信得过的万能型选手。
遣散刻下,摩尔线程已完成了四代全功能GPU的迭代,其中包括撑持FP8精度的最新智算卡MTT S5000、训推一体全功能智算卡MTT S4000、撑持千卡互联的第一代超大领域智算交融中心居品KUAE1,以考取二代万卡集群KUAE2,这些居品已内容托福多个智算中心。

那么,摩尔线程何如打造天下先进的AI工场?
这是一项系统级创新工程,主要体刻下五个关节方面:加快盘算通用性、单芯片灵验算力、单节点后果、集群后果和集群康健性,这些身分为德不终紊统筹兼顾。

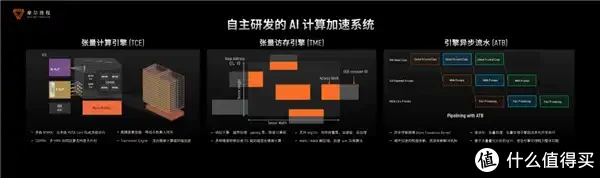
在加快盘算通用性方面,摩尔线程自主研发的多引擎全功能GPU,来源好意思满在单芯片架构,同期撑持AI盘算加快、图形渲染、物理仿真和科学盘算、超高清视频编解码,并阴事从FP8到FP64的全盘算精度。



不同精度的盘算适用于不同的应用场景,举例FP8用于混杂精度西席和诳言语模子推理,INT8用于量化推理和CV推理,BF16/FP16用于机器学习和诳言语模子西席,FP32/TF32用于3D渲染、游戏和高精度推理西席等,而FP64则主要用于科学盘算,如天气预告和风光仿真等。

摩尔线程的全功能GPU好像撑持以上全部精度的西席推理,从而好意思满AI西席推理、科学盘算、工业智能、自动驾驶、具身智能、生物制药、AIGC、AI智能体、游戏等全场景AI加快。
有了应用场景,性能跟不上那亦然蓦的,摩尔线程自研的MUSA架构从底层基础设施到中间层管制平台,再到表层应用,好意思满了全面阴事,通过盘算、通讯、存储期间创新,灵验擢升了单芯片灵验算力。


MUSA架构,是创新的多引擎、可伸缩GPU架构,通过硬件资源池化及动态资源退换期间,构建了全局分享的盘算、内存与通讯资源池。这一联想不仅打破了传统GPU功能单一的贬抑,还在保险通用性的同期权臣擢升了资源欺骗率。
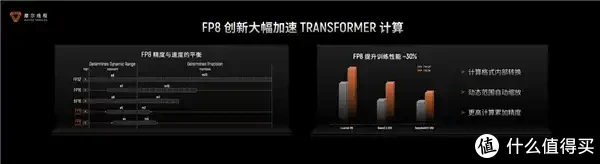
在盘算层面,摩尔线程的AI加快系统(TCE/TME)全面撑持INT8/FP8/FP16/BF16/TF32等多种混杂精度盘算。手脚国内首批好意思满FP8算力量产的GPU厂商,其FP8期间通过快速相貌革新、动态范围智能适配和高精度累加器等创新联想,在保证盘算精度的同期,将Transformer盘算性能擢升约30%。
此外,DeepSeek曾在期间论说中提到,在通讯流程中约15%的流式多处理器被占用,也便是差未几15%的算力莫得用到西席中,而是被用于通讯。
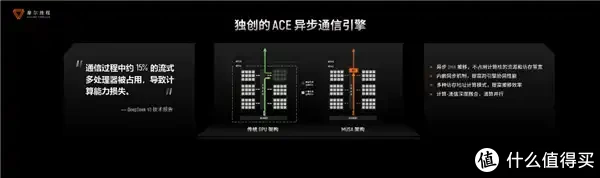
摩尔线程是何如治理这个问题的呢,基于自研的MTLINK 2.0好意思满的辘集通讯库,好意思满卡间高速互联,高放洋众人业平均水平60%的带宽;同期基于MTT S5000的异步通讯引擎,从而好意思满高效盘算与通讯并行,减少了15%的盘算资源损耗,为大领域集群部署奠定了坚实基础。

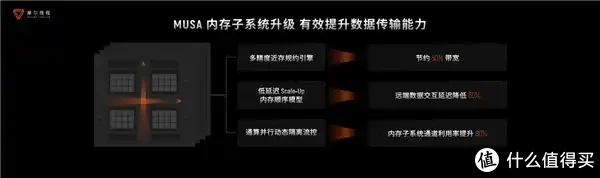
内存系统方面,通过多精度近存规约引擎、低延伸Scale-Up、通算并行资源阻遏等期间,好意思满了50%的带宽检朴和60%的延伸缩小。
有了单芯片的算力,还需要好意思满单节点的高后果,摩尔线程的MUSA全栈系统软件,通过高效的基础软件库,框架算法创新和完备的开发器用链擢升了单节点盘算后果。

在GPU驱动任务退换优化方面,摩尔线程的核函数脱手时辰仅为业界平均耗时的1/2,核函数脱手是指盘算任务从CPU主机传输到GPU开荒并现实的流程,传统方法中,较高的脱手延伸会导致算力资源糜费。而摩尔线程则撑持千次盘算教唆并行下发,从而大幅减少GPU恭候时辰。
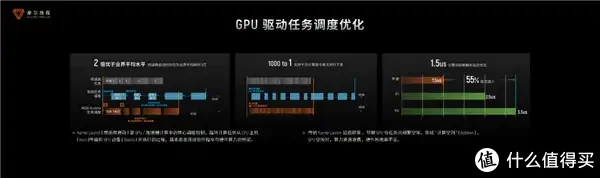


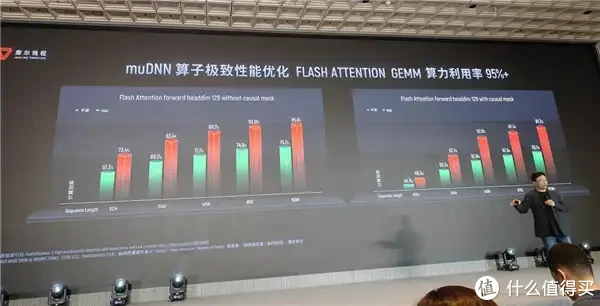
摩尔线程还对核默算子库进行了极致优化,比如GEMM算子算力欺骗率达98%,Flash Attention 算子算力欺骗率打破95%。
在通讯后果上,MCCL通讯库好意思满RDMA采集97%带宽欺骗率;基于异步通讯引擎优化盘算通讯并行,集群性能擢升10%。
在开发生态兼容上,基于Triton-MUSA编译器 + MUSA Graph 好意思满DeepSeek R1推理加快1.5倍,全面兼容Triton等主流框架。
此外,摩尔线程还提供了完好的开发者器用套件,如深度监控GPU并采集硬件性能数据的Torch Profiler,以及不错一键部署MUSA软件栈和AI作事步履的MUSA Deploy等。


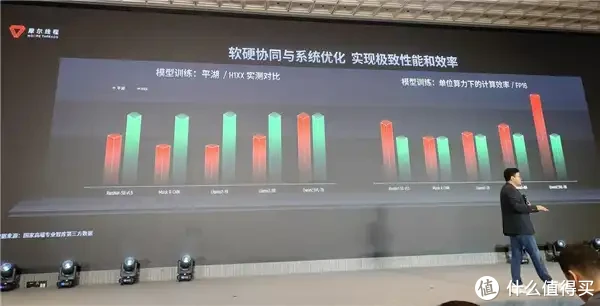
恰是这种软硬协同与系统优化,好意思满了极致性能和后果,从平湖和国外主流GPU居品的实测对比数据中,咱们不错直不雅地看到摩尔线程居品的上风。
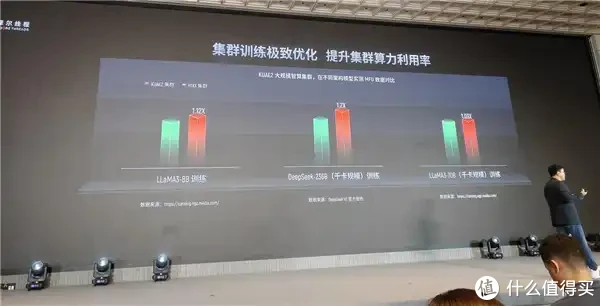
在集群方面,如前文所述,摩尔线程领有撑持千卡互联的KUAE1和撑持万卡互联的第二代决策KUAE2,并好意思满了模子种类全撑持,不管何种类型的模子都能适用,这亦然信得过满足AI工场使用和好意思满的场地。




把柄官方分享的数据,KUAE2在不同架构模子的实测MFU数据对比中,性能和后果均处于行业进步水平。
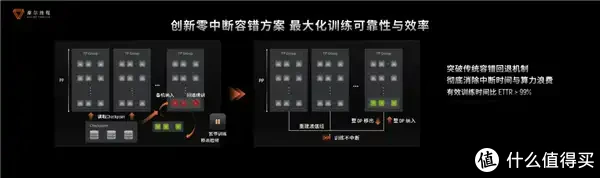
临了亦然最紧迫的少许,那便是康健性,集群不彊壮的话,再高的性能再快的后果也莫得任何有趣有趣,为此摩尔线程推出了零中断容错期间,故障发生时仅阻遏受影响节点组,其余节点连续西席,备机无缝接入,全程无中断,这也使得KUAE集群灵验西席时辰占比超99%。

针对集群中的慢节点,摩尔线程开发了一套多维度Training Insight,将卓越处理后果擢升了50%,都集集群巡检与升起查验,西席奏服从及速率提高了10%。

玄虚来看,摩尔线程的高效AI工场都集了全功能GPU、MUSA架构、MUSA软件栈、KUAE集群和零中断期间,为AI大模子西席提供了遍及可靠的基础设施撑持,况且只须这么的组合,才能确保每一个要领都达到最好景况。

大模子西席完成后,还需要进行推理考证,摩尔线程的推表示决决策基于MT Transformer自研推理引擎、TensorX自研推理引擎和vLLM-MUSA推理框架,为模子考证和部署提供极致性能撑持。


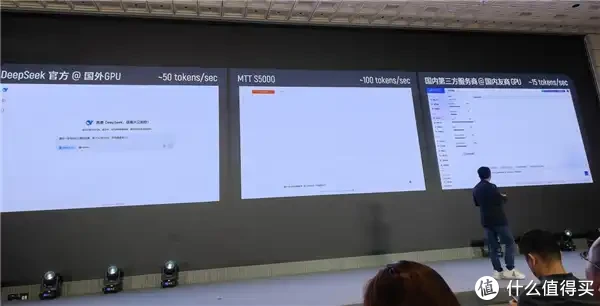
通过实测,MTT S5000设立了DeepSeek全量模子推理速率的新标杆:跑满血DeepSeek R1推理模子,速率达到100 tokens/s。
GPU不错说是AI期间最稀缺的资源之一,亦然大国科技竞争的焦点,其紧迫性显而易见。咱们深知硬科技研发的疼痛,但摩尔线程仍是接管了通用性最强、难度最高的全功能GPU阶梯。
从全功能GPU的研发世博体育,到“AI工场”认识的建议与现实,摩尔线程这条说念路天然充满挑战,但它无疑是好像走得最长久的旅途。将来,咱们期待摩尔线程好像赓续打破期间瓶颈,以更遍及的算力、更高效的架构、更康健的性能,为国产AI的发展注入坚决能源。
